As part of my on-going parallel-programming series (hopefully…) on communication patterns in Nek5000, this note accompanies my recent work on Nek5000/PR#856 and focuses on element migration (or re-distribution) for restarts. The same protocols also apply to all-to-all routines such as gfldr and findpt, where the latter is also used in neknek.
Restart Procedure
The latest solution from previous simulations is saved into a checkpoint file, which stores the fields element-wisely but not necessarily following the same elements ordering. Instead, the elements are dumped from MPI-IO with an integer lookup for the elements id.
To resume the simulation, the code
- Read the data via MPI-IO,
- Distribute the elements to corresponding MPI ranks, and
- Pre-process the data e.g. interpolating between polynomial orders
By default, Nek5000 writes to a single file. It also supports a multi-file I/O mode that groups MPI ranks and combines steps (1) and (2) to reduce per-file size and communication. Here, we focus only on Step 2.
Communication Setup
After Step 1, each MPI rank has read an evenly sized chunk of the checkpoint ($\pm 1$ element), yielding nelr local elements. For each local element el = 1, 2, ..., nelr, assign its global ID eg = er(el), where er is the checkpoint’s local-to-global lookup table. Given the target partition from the nominal simulation, the task of migration is simply to send element eg to its owner rank glleid(eg) and insert it at local index gllel(eg).
Using the parcel analogy:
- Local parcel label from a sender:
el = 1, 2, ..., nelr - Global tracking number
eg = er(el) - Destination country (owner rank):
gllnid(eg) - Address at destination (owner’s local index):
gllel(eg)
Here is a pseudo-code for pairwise communication:
1
2
3
4
5
6
7
8
9
10
11
do nid = 1,np ! all MPI ranks
do el = 1,nelr ! go through read elements
eg = er(el) ! global index
jnid = gllnid(eg) ! dest. rank
jeln = gllel(eg) ! dest. local index
! Send data(:,el) from rank nid to jnid's jeln position
enddo
enddo
Alltoallv
One can start with MPI_Alltoallv, which is a collective call moves many-to-many data (See image below). The “v” lets each rank send/receive irregular counts to/from every other rank. The typical workflow is:
- Pack. Sort local items by destination, count data size and displacements.
- Exchange. Call
MPI_Alltoallvto transfer the packed buffers. - Place. Unpack on receipt and place each item at its local index.
The limitation of alltoallv is, it’s optimized for dense communication patterns, but our restart redistribution is sparse and can be highly irregular. Each rank typically talks to a small subset of ranks (due to clustering from the old and new partitions) rather than all ranks. In this regime, the collective’s global synchronization and $O(P)$ metadata overhead can dominate, reducing efficiency and scalability 1.
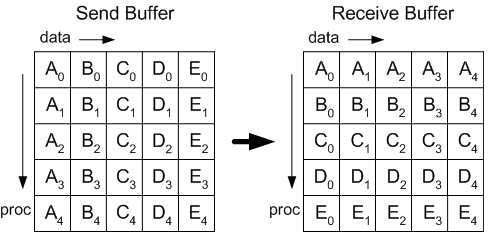 MPI Alltoall: Image from Cornell Virtual Workshop of MPI Collective Communication
MPI Alltoall: Image from Cornell Virtual Workshop of MPI Collective Communication
RMA (Remote-Memory-Access)
Each rank allocates a receive window large enough for incoming data and exposes it to the MPI communicator, effectively creating virtual shared memory. Peers then write directly into this window using one-sided operations. We simply issue MPI_Put to send the data to the destination memory offset. Because element updates are independent and their relative ordering doesn’t matter, no extra handshakes are needed beyond the window epoch boundaries. On RDMA (Remote-Direct-Memory-Access) capable hardware, these puts can be offloaded to the NIC for additional speed.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
! expose memory "wk" via a window
disp_unit = 4
call MPI_Win_create(wk, win_size, disp_unit, MPI_INFO_NULL, commrs, rsH, ierr)
! open an epoch
call MPI_Win_lock_all(0,rsH,ierr)
l = 1
do el = 1,nelr
eg = er(el)
jnid = gllnid(eg)
jeln = gllel(eg)
disp = (jeln-1)*nxyzr
! put w2(l : l+nxyzr-1) to jnid's window at offset disp
call MPI_Put(w2(l),nxyzr,MPI_REAL4,jnid,
disp, nxyzr,MPI_REAL4,rsH,ierr)
l = l + nxyzr
enddo
! close epoch, updates are now visible
call MPI_Win_unlock_all(rsH,ierr)
! unpack: copy from wk to Nek arrays
A potential drawback of RMA is its dependence on the underlying network (often RDMA) and vendor implementation. Behavior and performance can vary across systems, and driver/firmware updates may introduce regressions or bugs, making portability and debugging harder.
Crystal Router (Fox, 1988)
The crystal router (CR) is a hypercube-style protocol that moves the data across all ranks in a fixed number of stages. It’s effective for sparse all-to-all exchanges.
Let $P = 2^d$ MPI ranks, with rank ID are encoded in $d$ binary bits. Define $b_c(k) = \left\lfloor \frac{k}{2^{\,c-1}} \right\rfloor \bmod 2$ as the $c$-th bit (1-based) of integer $k$. At stage $c$ ($c=1,…,d$), suppose an element eg destined for rank jnid is currently at rank knid. Compare the $c$-th bit of jnid and knid:
- If the bits differ, transfer the element to
knid’s $c$-th partner obtained by flipping that bit: \({\rm partner} = {\rm knid} + (-1)^{b_c({\rm knid})}\ 2^{c-1}\) - If the bits match, keep the element local for this stage.
Each stage fixes at most one differing bit between the current rank and the destination. After $d$ stages, all bits match, so every element reaches its owner. CR is optimal on a hypercube network because at stage $c$, each rank communicates only along the $c$-th hypercube dimension with a unique partner, avoid link conflict.
1
2
3
4
5
6
7
8
9
10
for stage c = 1,...,d
for mail in output_mail:
if b_c(destinatoin) != b_c(current process id):
Add mail to com_buf
Exchange com_buf through the channel c to its partner rank
for mail in com_buf:
if this processer is (one of) the destination:
Copy mail to input_mail
if we need to forward this mail:
Copy mail to output_mail
In gslib CR (sarray_transfer) is implemented with basic MPI send/recv. It’s portable, reliable and proven effective in Nek5000. The worst case of the CR is to have a bad initial element distribution such that they arrive at one particular rank at the same time. This results huge traffic volume and can exceed MAX_INT in practice.
Batched Restart
To avoid peak traffic in CR and excessive memory footprint in RMA, we throttle transfers in batches. Like all states capping daily entries to 1,000 cars (while allowing pass-through), we send data in batches: choose a destination-index range and only let element in that batch participate in the exchange. This slows communication (extra rounds, more overhead) but gives traffic control and helps avoid worst-case spikes.
Conclusion
- alltoallv: Slow, not optimized for sparse patter, doesn’t really scale.
- RMA: Fast, can be further optimized based on hardware or network, but relies on vendor and can easily break after a system update.
- Crystal router: Low level MPI calls via gslib, but can have huge volume of traffic. Can have extra network congestion.
- Batched restart: reduce communication volume. Trade speed with robustness.
Wrapping up: the goal of Nek5000/PR#856 adds the existing crystal router (CR) as a fallback restart path, with batched transfers for scalability. We’ve seen RMA break on some HPC systems, especially after software upgrade. CR isn’t usually the fastest, but when RMA doesn’t work, CR delivers a practical infinite speedup: from not running to running.
Balaji, P. et al. (2009). MPI on a Million Processors. In: Ropo, M., Westerholm, J., Dongarra, J. (eds) Recent Advances in Parallel Virtual Machine and Message Passing Interface. EuroPVM/MPI 2009. Lecture Notes in Computer Science, vol 5759. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-03770-2_9 ↩